Description
In this course, you will learn:
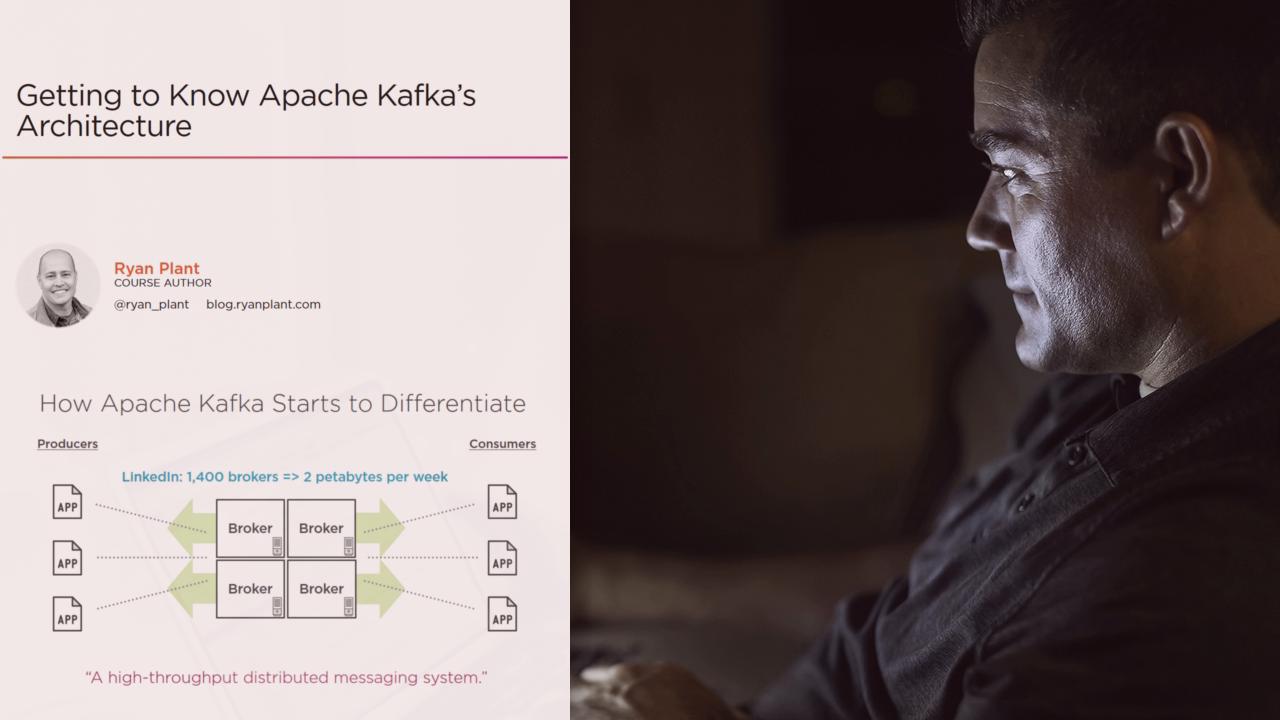
- Developed at LinkedIn, Apache Kafka is a distributed streaming platform that provides scalable, high-throughput messaging systems in place of traditional messaging systems like JMS.
- In this course, examine all the core concepts of Kafka. Ben Sullins kicks off the course by making the case for Kafka, and explaining who's using this efficient platform and why.
- He then shares Kafka workflows to provide context for core concepts, explains how to install and test Kafka locally, and dives into real-world examples.
- By the end of this course, you'll be prepared to achieve scalability, fault tolerance, and durability with Apache Kafka.
Syllabus:
- Introduction
- Why are Kafka skills so high in demand?
1. Introduction to Kafka
- What is Kafka?
- Prerequisites for the course
- Kafka scaling and resiliency
- Setting up the exercise files
2. Kafka Scaling Concepts
- Clusters and controllers
- Replication
- Partition leaders
- Mirroring
- Security
3. Building a Kafka Cluster
- Kafka cluster setup
- Running the cluster
- Creating topics with replication
- Kafka cluster in action
- Kafka resiliency in action
4. Building Scalable Producers
- Producer internals
- Producer publishing options
- Acknowledgments in Kafka
- Additional producer parameters
- Java producer options example
5. Building Scalable Consumers
- Consumer: How it works
- Batching message consumption
- Committing messages
- Java consumer example
- Multi-threaded consumers
6. Kafka Best Practices
- Managing partition counts
- Managing messages
- Managing consumer settings
- Managing resiliency
7. Use Case Project
- Kafka applications use case: Problem definition
- Setting up topics
- Producing data in Java
- Consuming data in Java






![Apache Kafka for Beginners - Second Edition[Updated Mar2020]](https://i.udemycdn.com/course/240x135/1146104_b73e_16.jpg)