Description
In this course, you will :
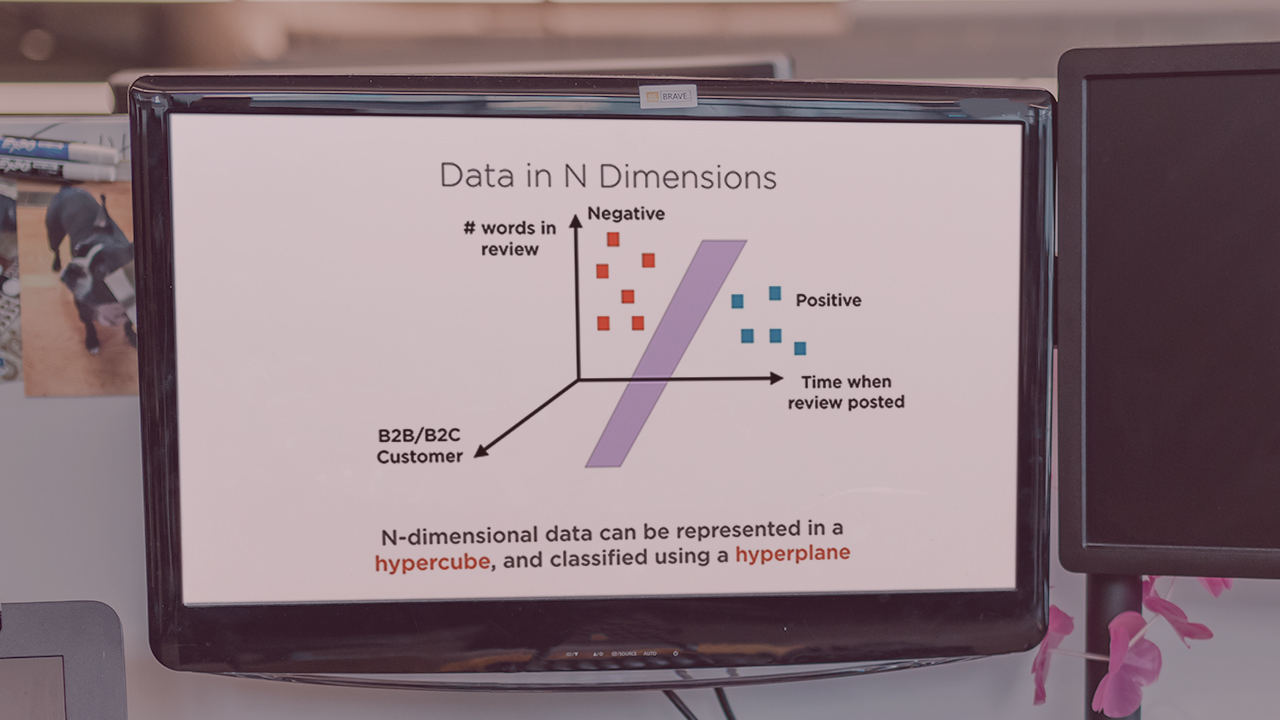
- Learn how to solve problems with large, high-dimensional, and potentially infinite state spaces.
- See that estimating value functions can be cast as a supervised learning problem---function approximation---allowing you to build agents that carefully balance generalization and discrimination in order to maximize reward.
- Begin this journey by investigating how our policy evaluation or prediction methods like Monte Carlo and TD can be extended to the function approximation setting.
- Learn about feature construction techniques for RL, and representation learning via neural networks and backprop.