Description
This course will look at regularised linear regression models for prediction and feature selection. You will be able to handle very large feature sets and choose between models of varying complexity. You'll also look at how different aspects of your data, such as outliers, affect your chosen models and predictions. You will use optimization algorithms that scale to large datasets to fit these models.
Syllabbus :
1. (A) Welcome
- Welcome!
- What is the course about?
- Outlining the first half of the course
- Outlining the second half of the course
- Assumed background
(B) Simple Linear Regression
- A case study in predicting house prices
- Regression fundamentals: data & model
- Regression fundamentals: the task
- Regression ML block diagram
- The simple linear regression model
- The cost of using a given line
- Using the fitted line
- Interpreting the fitted line
- Defining our least squares optimization objective
- Finding maxima or minima analytically
- Maximizing a 1d function: a worked example
- Finding the max via hill climbing
- Finding the min via hill descent
- Choosing stepsize and convergence criteria
- Gradients: derivatives in multiple dimensions
- Gradient descent: multidimensional hill descent
- Computing the gradient of RSS
- Approach 1: closed-form solution
- Approach 2: gradient descent
- Comparing the approaches
- Influence of high leverage points: exploring the data
- Influence of high leverage points: removing Center City
- Influence of high leverage points: removing high-end towns
- Asymmetric cost functions
- A brief recap
2. Multiple Regression
- Multiple regression intro
- Polynomial regression
- Modeling seasonality
- Where we see seasonality
- Regression with general features of 1 input
- Motivating the use of multiple inputs
- Defining notation
- Regression with features of multiple inputs
- Interpreting the multiple regression fit
- Rewriting the single observation model in vector notation
- Rewriting the model for all observations in matrix notation
- Computing the cost of a D-dimensional curve
- Computing the gradient of RSS
- Approach 1: closed-form solution
- Discussing the closed-form solution4m
- Approach 2: gradient descent
- Feature-by-feature update
- Algorithmic summary of gradient descent approach
- A brief recap
3. Assessing Performance
- Assessing performance intro
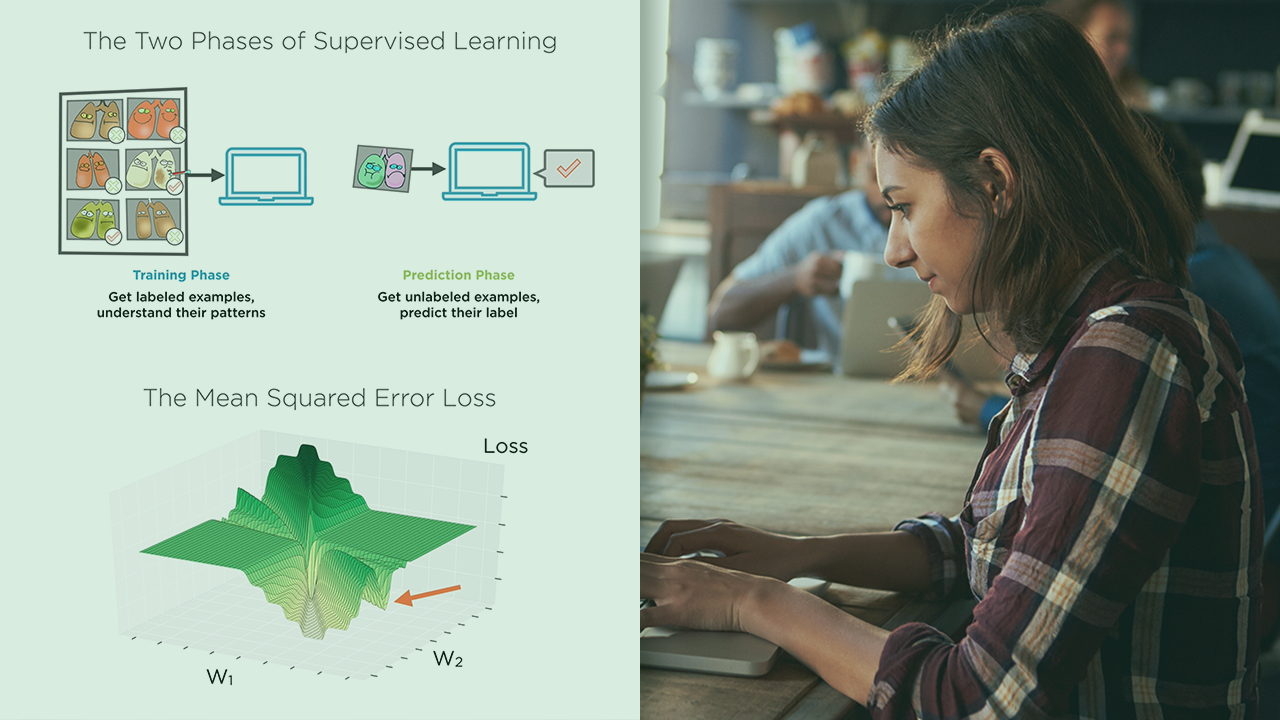
- What do we mean by "loss"?
- Training error: assessing loss on the training set
- Generalization error: what we really want
- Test error: what we can actually compute
- Defining overfitting
- Training/test split
- Irreducible error and bias
- Variance and the bias-variance tradeoff
- Error vs. amount of data
- Formally defining the 3 sources of error
- Formally deriving why 3 sources of error
- Training/validation/test split for model selection, fitting, and assessment
- A brief recap
4. Ridge Regression
- Symptoms of overfitting in polynomial regression
- Overfitting demo
- Overfitting for more general multiple regression models
- Balancing fit and magnitude of coefficients
- The resulting ridge objective and its extreme solutions
- How ridge regression balances bias and variance
- Ridge regression demo
- The ridge coefficient path
- Computing the gradient of the ridge objective
- Approach 1: closed-form solution
- Discussing the closed-form solution
- Approach 2: gradient descent
- Selecting tuning parameters via cross validation
- K-fold cross validation
- How to handle the intercept
- A brief recap
5. Feature Selection & Lasso
- The feature selection task
- All subsets
- Complexity of all subsets
- Greedy algorithms
- Complexity of the greedy forward stepwise algorithm
- Can we use regularization for feature selection?
- Thresholding ridge coefficients?
- The lasso objective and its coefficient path
- Visualizing the ridge cost
- Visualizing the ridge solution
- Visualizing the lasso cost and solution
- Lasso demo
- What makes the lasso objective different
- Coordinate descent
- Normalizing features
- Coordinate descent for least squares regression (normalized features)
- Coordinate descent for lasso (normalized features)
- Assessing convergence and other lasso solvers
- Coordinate descent for lasso (unnormalized features)
- Deriving the lasso coordinate descent update
- Choosing the penalty strength and other practical issues with lasso
- A brief recap
6. (A) Nearest Neighbors & Kernel Regression
- Limitations of parametric regression
- 1-Nearest neighbor regression approach
- Distance metrics
- 1-Nearest neighbor algorithm
- k-Nearest neighbors regression
- k-Nearest neighbors in practice
- Weighted k-nearest neighbors
- From weighted k-NN to kernel regression
- Global fits of parametric models vs. local fits of kernel regression
- Performance of NN as amount of data grows
- Issues with high-dimensions, data scarcity, and computational complexity
- k-NN for classification
- A brief recap
(B) Closing Remarks
- Simple and multiple regression
- Assessing performance and ridge regression
- Feature selection, lasso, and nearest neighbor regression
- What we covered and what we didn't cover
- Thank you!