
Description
Deep learning has transitioned from an academic research topic to the foundational technology powering modern artificial intelligence, including computer vision, natural language generation, and autonomous decision-making engines. This course provides a robust, code-first introduction to building, training, and deploying deep neural networks from the ground up. Aimed at demystifying the complex mathematics behind artificial intelligence, the curriculum bridges the gap between high-level algorithmic concepts and practical, local execution using industry-standard libraries like TensorFlow and Keras. Rather than presenting deep learning as an abstract "black box," you will follow a highly structured learning path that starts with simple artificial neurons and progresses systematically to sophisticated multi-layer architectures. Through clear explanations and intensive, hands-on coding labs, you will gain a strong intuition for how data passes through deep pipelines, how models dynamically learn from errors, and how to optimize neural weights to handle complex, non-linear real-world problems.
Topics This Course Covers
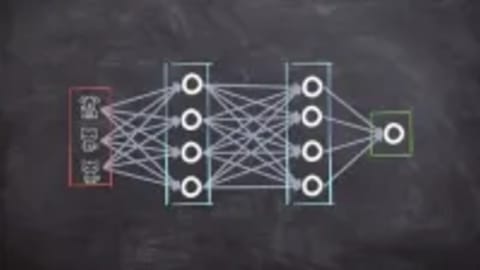
- Foundations of Neural Architectures: Building a concrete mental model of artificial neurons, layer connections, and the mathematical mechanics of deep networks.
- Data Preparation for AI Models: Processing, scaling, and structuring raw input features to make them suitable for efficient neural network training cycles.
- Forward and Backward Propagation: Demystifying how information flows forward to generate an output prediction and how errors backpropagate to fine-tune network weights.
- Activation Functions and Non-Linearity: Implementing and configuring critical non-linear activation functions such as ReLU, Sigmoid, and Tanh within hidden layers.
- Loss Functions and Optimization Techniques: Utilizing loss functions to measure model error and leveraging gradient descent optimizers to systematically maximize network accuracy.
- Overfitting and Model Regularization: Deploying practical engineering strategies such as dropout layers, early stopping, and validation tracking to ensure models generalize well to unseen datasets.
Who Will Benefit Taking This Course
- Aspiring Data Scientists and AI Engineers: Programmers and analysts who want to move past traditional statistical machine learning and master deep learning architectures.
- Computer Science Students and Researchers: Academic learners seeking a structured, clear, and highly practical supplement to theoretical artificial intelligence coursework.
- Software Developers: Backend or full-stack engineers looking to future-proof their skill sets by learning how to natively integrate predictive deep learning models into software ecosystems.
- Tech Professionals and Analytics Managers: Technical leaders who need a grounded, math-backed understanding of neural networks to effectively oversee AI-driven product developments.
Why Take This Course
The professional demand for engineering talent capable of building and optimizing custom neural networks is growing at an unprecedented rate. Relying purely on third-party APIs limits your ability to innovate; true competitive advantage belongs to engineers who understand the internal mechanics of hidden layers, optimization curves, and feature extractions. This course cuts through the overwhelming academic jargon to provide a clean, highly illustrative development roadmap that establishes deep intuition before writing code. It systematically eliminates the typical math frustration by linking calculus concepts directly to practical code parameters. By completing this foundational training, you will bridge the gap between basic coding and advanced artificial intelligence engineering, acquiring the exact technical confidence needed to design, debug, and deploy enterprise-grade deep learning systems.








