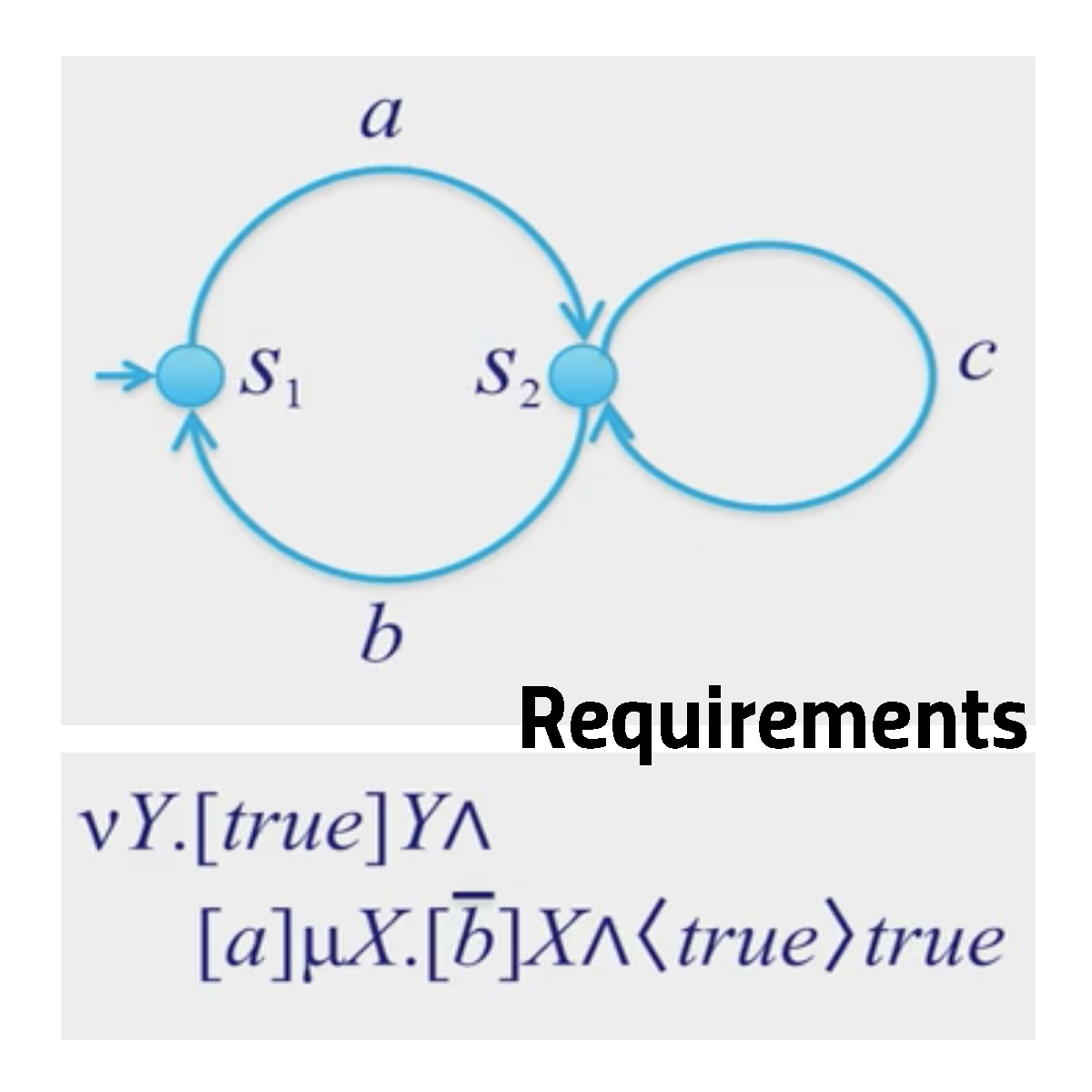
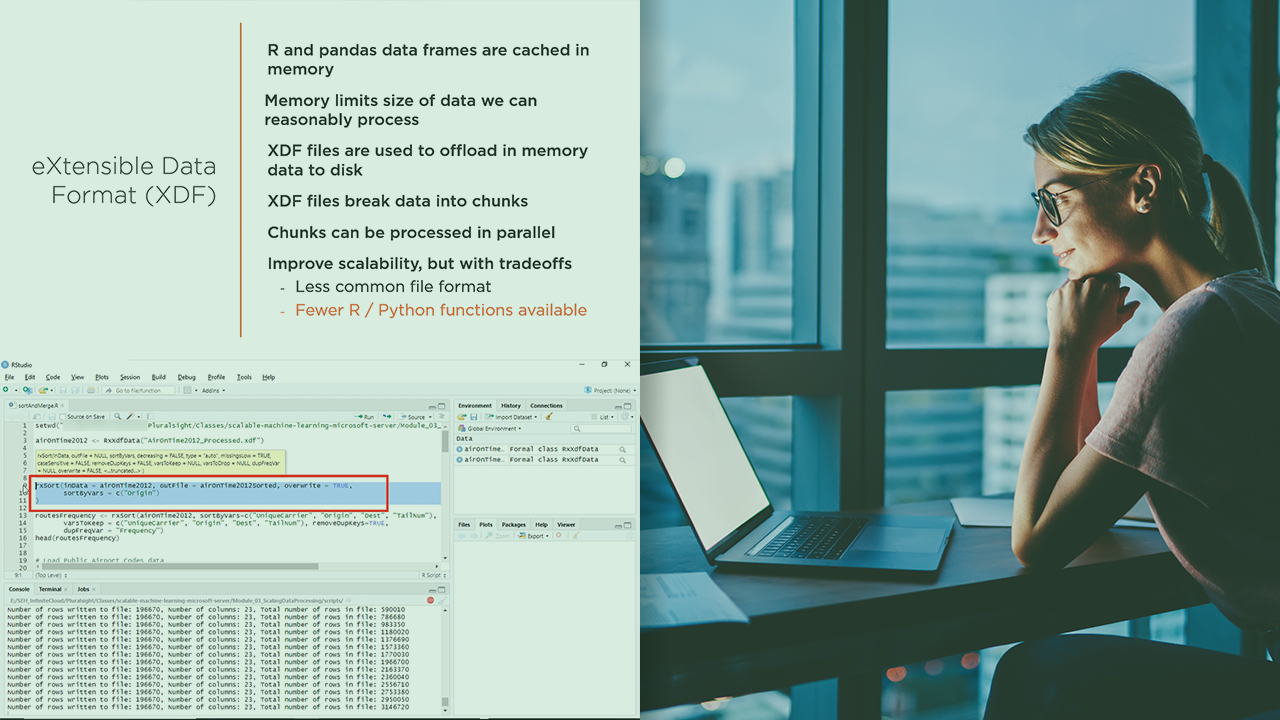
Description
In this course, you will :
- Learn the fundamentals of data clustering and how to use the K-means algorithm to cluster data.
- Single Linkage Clustering and DBSCAN, a clustering method that captures the insight that clusters are dense groups of points, are used to cluster data.
- Gaussian Mixture Models are used to cluster data, and Expectation Maximization is used to optimise Gaussian Mixture Models.
- Principal Component Analysis and Independent Component Analysis are used to reduce the dimensionality of the data.
- Discover a wide range of techniques such as hierarchical and density-based clustering, gaussian mixture models, cluster validation, principal component analysis (PCA), and independent component analysis (ICA).
Syllabus :
- Clustering
- Hierarchical and Density-Based Clustering
- Gaussian Mixture Models
- Dimensionality Reduction